With the article about a performance mystery involving Java and BitSets, I got help from Hacker News (and a lot of other sources as well) to investigate and also solve the mystery.
However, I haven’t managed to solve the problem that this NUMA (+ Docker, in my case) issue is causing me.
I'm very happy I could find the solution to this mystery. But the solution is quite unsatisfactory for my particular problem, since I can't use `numctl --membind=0` in the drag-racing environment. Have a look at my bitset solution's results here: https://t.co/qPakybLMAw 😭
— Peter Strömberg aka PEZ (@pappapez) February 9, 2022
Let me try to summarize the issue as best as I understand it:
When an application needs to mutate some allocated memory as quickly as possible, it benefits greatly from the thread running in the same NUMA node as where that memory is allocated. (Or gets a huge penalty if the thread and the memory are bound to different NUMA nodes, depending on half-full or half-empty glass.)
A symptom that your app could be affected is that some hot path performs very differently between runs. In my case I see a 50% performance drop about 60% of the times.
This can of course vary a lot between environments where the application is run. In my case I performance tested my function heavily on my M1 Mac, where I didn’t see any flakyness in the performance. I noticed the symptom because the particular application happens to be something being run as part of a huge benchmarking project, mostly on Linux machines, and always i Docker. Agical bought me a similar Linux machine and when I ran my performance tests there, I could only reproduce it when run in Docker.
So, the first take away for me here is to remember to ask myself if I am testing performance in a relevant environment.
Next question is what can be done about this, and I am not going to withhold what I have learned about that so far. Let me start by noting: I actually think I might be wrong in framing this as a NUMA issue. It is probably rather that NUMA is the solution. Because, for my particular function, being single threaded and heavily manipulating the same allocated memory area over and over again in its hot path, I could get stable (and good) performance by pinning the JVM process and the memory it accesses to the same NUMA node. Like so:
numactl --cpunodebind=0 --membind=0 java <options> <main class>`My guess is that for multithreaded processes, you will have to pay the price that some threads migrate outside the node where the memory is being mutated. Maybe there is a way to guarantee that at least one of the threads is co-located?.
OK, but it works for my sieve, so how does this not solve my problem? Oh, that is because that to bind the memory when run in Docker, the container needs to run in privileged mode. In my case:
docker run --privileged --rm -it primes-java-bitsetThis is not how the containers are run in the drag-racing benchmark. Consider this benchmark run [from today]:
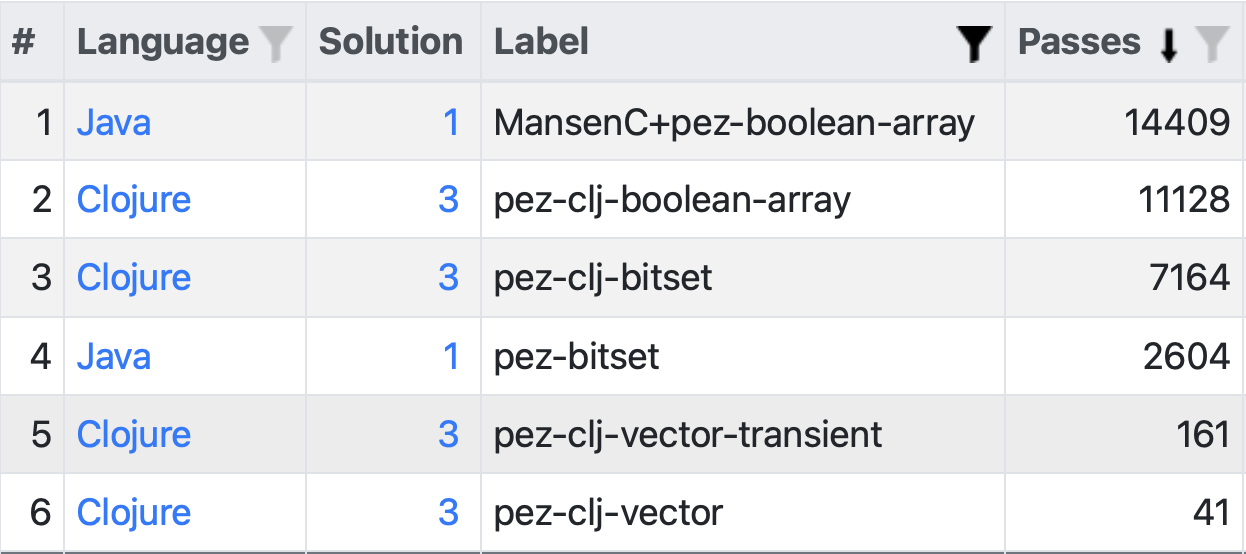
These are my implementations of the sieve for the drag-racing
benchmark. MansenC+pez-boolean-array and
pez-clj-boolean-array are as same as two implementations
can be in Java and Clojure. These do not seem to be affected. I don’t
know why, someone with a better understanding about memory allocation
for native Java arrays might know.
The problem is being beautifully exposed for the
pez-clj-bitset (Clojure) and pez-bitset (Java)
entries. Again the same solutions (the Clojure code compiles to
something extremely similar to what the hand coded Java compiles to in
for these). The Clojure version managed 7164 passes in 5 seconds, while
the Java version only managed 2604! This is because in this particular
run, the Clojure version happened to be run with the memory allocated on
the same NUMA node as where where the JVM was running, but this was not
so for the Java version. (This time.)
Can’t I use the Java option -XX:+UseNUMA, instead? In
fact I am doing that for my Java solutions in the benchmark, and you can
clearly see that it doesn’t help. I’ve gotten this explained to me on
LinkedIn, by Claes Redestad, like so:
+UseNUMAmight resolve certain types of NUMA issues, but not all. Depending on which GC you use that flag might mainly ensure the heap is neatly split across NUMA nodes and that mutator threads will try and allocate to areas which are node local. Once objects migrate to old generation things get murkier. IIRC long-lived data structures - like the one in your test - will end up at an arbitrary memory node.
Claes works at Oracle. I assume he works with Java. Regardless, he really seems to know what he is talking about!
There it is. I hope you have learnt at least something. I know I learnt a lot while figuring some of these things out.
I think I am out of luck trying to work around the problem with not being able to run the Docker container in privileged mode, if you know of something I could try, please let me know. But where, when there is no comment section here? I’ll tweet this and also start a thread over at HN. Please comment on one of those.
Here’s the tweet:
Follow-up to that BitSet performance mystery article. Mystery solved, but not the problem! https://t.co/j82s8Xbfev
— Peter Strömberg aka PEZ (@pappapez) February 9, 2022
And here’s the Hacker News post.
And while asking you for help, there is one more thing I’d like to know. OK two actually:
- On my Mac my
boolean-arraysolutions run suspiciously much faster than myBitSetsolutions. I wonder if this split allocation of the JVM and the memory is always happening. Could that be so? - Is there a way to control this allocation on Mac? There is no NUMA there, if I understand things correctly.
Thanks in advance for any help with the problems described here.
Happy controlling of them NUMA nodes! ❤️
Peter Strömberg 

Peter Strömberg is an autodidact programming nerd living in Stockholm, Sweden. He has been all over the (coder) place for a long time. After some 20 years in the profession he made an attempt to leave it for another passion of his: Product. That attempt ended when Peter was introduced to Clojure and he felt how it gave him back all the joy of programming, and then some.
You can contract Peter for remote Clojure/ClojureScript gigs up to 80% of an FTE. The other 20% Agical pays him to spend doing open source work. Most often this is about maintaining Calva, a popular Visual Studio Code Clojure IDE extension which Peter created 2018.
- E-mail: peter.stromberg@agical.se
- LinkedIn: Peter (PEZ) Strömberg
- Twitter: @pappapez